
This is the 5th post in a seven-part series about g2p. In this post, we discuss using g2p to create interactive text/audio books with ReadAlong Studio.
G2P Blog Series Index
- Background
- How to write a basic mapping in G2P Studio
- Writing mappings on your computer
- Advanced mappings
- ReadAlong Studio & Other Applications
- Preprocessing mappings
- Contributing
This post will discuss the use of g2p in the ReadAlongs project for creating interactive audio/text documents.
Other Applications
There are number of different software tools that are already making use of g2p. For general purpose use in Python, have a look at this post.
Convertextract
Convertextract is a tool that lets you use g2p mappings to convert text inside a variety of different documents, including Microsoft Office documents like Powerpoint and Word coduments. Have a look at the convertextract repo readme or at Fineen Davis’ blog post about the Convertextract GUI.
ReadAlongs
ReadAlongs is a research project from the National Research Council’s Indigenous Language Technology Project.
Communities engaged in language revitalization have potentially many different recordings of their language and some associated text, but mobilizing these materials into something that is educationally useful can be time consuming. It’s also tough from the learner’s perspective to try and follow along the text (maybe a Word Document) just by simply playing the audio. It’s easy to get lost in the recording quickly, and from personal experience, trying to do that usually involves a lot of frustrating rewinding.
What if we could develop a tool that automatically figured out what parts of the audio file corresponded to what parts of the text? In Natural Language Processing, this is called forced alignment, and this is fundamentally what the ReadAlongs project does. But how does it do it? In part, by using a whole bunch of g2p mappings!
First of all, it’s good to know that forced alignment is essentially a “solved problem” for languages with a lot of data, thanks to people like David Huggins-Daines who is a collaborator on the ReadAlongs project. And, if you know Python, and have sentence-aligned parallel audio/text data in your language, you can train a model using one of the several tools out there developed for this task, like the Montreal Forced Aligner. But what if you don’t have that much data (or any) and what if you don’t know Python? If your language has a g2p mapping between its writing system and the IPA, you can likely circumvent that whole process. Here’s how:
We take a model for doing forced alignment on English and we manually write a g2p mapping from the writing system to IPA for the language we want to make a ReadAlong for. For example’s sake let’s say, Kanyen’kéha (Mohawk). This step requires somebody who is both familiar with the writing system used, and with the International Phonetic Alphabet.
Then, we use the very cool Python library PanPhon to figure out the mapping between the IPA characters in Mohawk and their closest IPA equivalents in English. We call this mapping a “Kanyen’kéha IPA to English IPA” mapping. If you have already created your mapping between the orthography and the IPA, you can generate this “Kanyen’kéha IPA to English IPA” using the g2p command line.
Then, we convert the ReadAlong in question from its original orthographic form all the way to English IPA (well, actually to ‘Arpabet’ which is an ASCII-compliant phonetic transcription standard that the alignment model understands).
Then, after we “do the alignment” (ie figure out which parts of the audio correspond to which parts of the text), ReadAlongs puts it all back together again and ta-da! There is your aligned audio and text! Keep reading to see how to generate an X-to-English IPA mapping for your language.
Generate your mapping between your language’s IPA and English IPA
After installing g2p and once you have made your mapping, update g2p by running g2p update. When you add or modify any mapping, g2p doesn’t actually see it yet. g2p update is what scans all the mappings and makes them available to g2p. Then, you can run g2p generate-mapping <input-code> --ipa. So in our example for Kanyen’kéha (moh) we would run
g2p generate-mapping moh --ipa
That will automatically generate a moh-ipa to eng-ipa mapping in g2p/mappings/langs/generated - do not edit this file or its configuration unless you really know what you’re doing, because it will get overwritten. After generation, you can run g2p update again and your mapping will be usable within g2p!
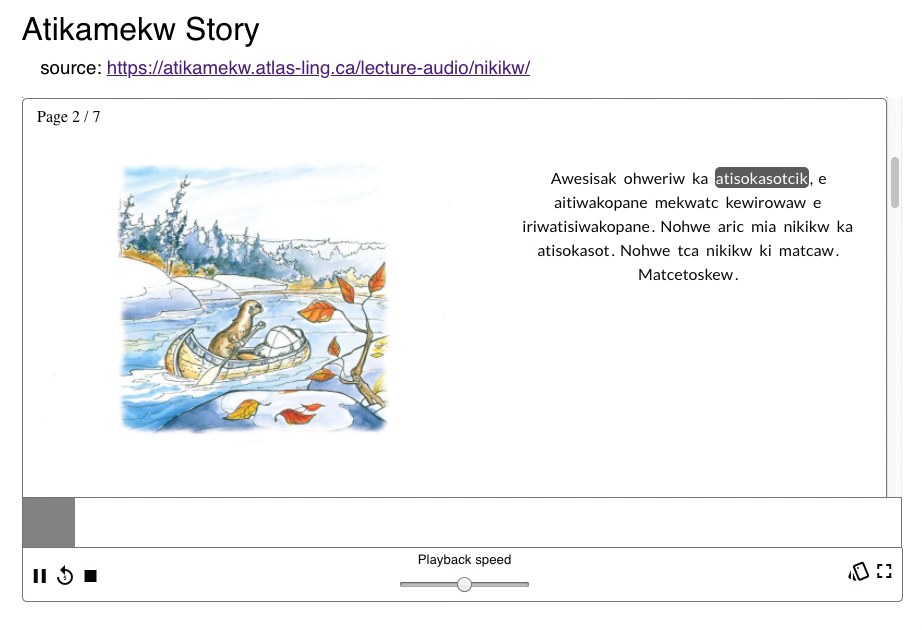
Visualizing the process
This is actually where the introductory picture to this blog series comes from! In the graphic below, you can see the word ‘bonjour’ in French converted to its IPA transcription. Then, its IPA transcription gets converted into its corresponding English IPA transcription based on the generated mapping (notice how uvular /ʁ/ gets transformed to alveolo-palatal /ʒ/). Then finally, the English IPA form is converted to Arpabet. So in all, we have an input of ‘bonjour’ that gets output as ‘B AO N ZH UW ZH’ and the aligner runs on that form.
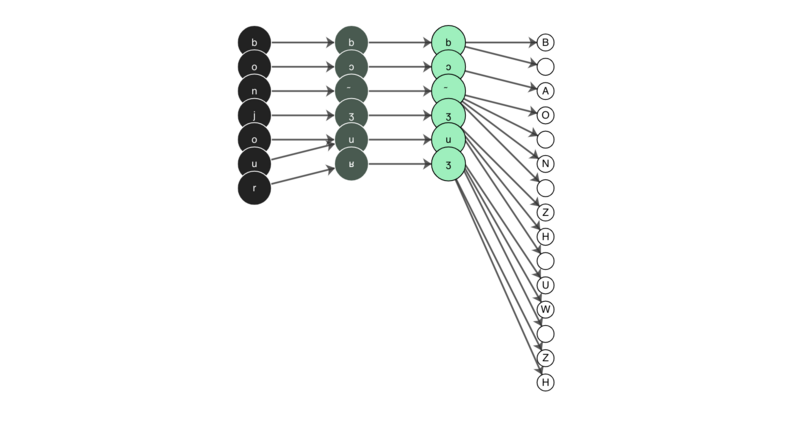
You can recreate this type of animation using the G2P studio by selecting the French (fra) to English Arpabet (eng-arpabet) mapping, choosing ‘animate’ and then typing your text in the input area as seen below:
What can you do with your aligned audio/text?
ReadAlongs exports to a variety of formats, including epub (for e-readers), Praat TextGrids, ELAN files, various subtitle formats, and an embeddable web component for your website.
Below is an example of the embeddable web component in Danish.